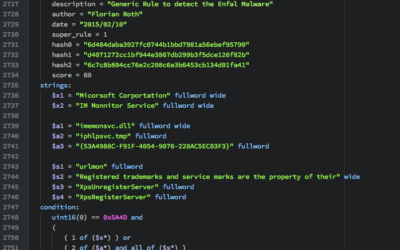
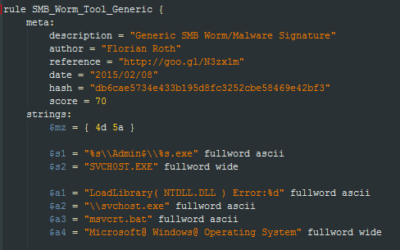
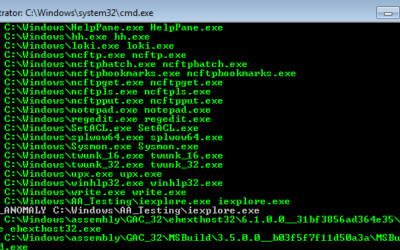
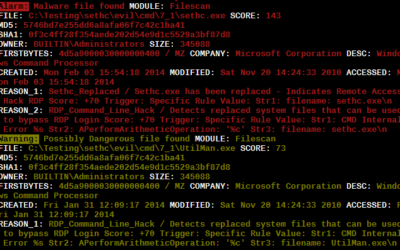
Have you already heard about THOR Thunderstorm, a self-hosted THOR as a service? In this blog post, we will show how you can leverage THOR Thunderstorm to level up your email infrastructure security.THOR Thunderstorm is a web API wrapped around THOR, which accepts...
Supercharging Postfix With THOR Thunderstorm
read more